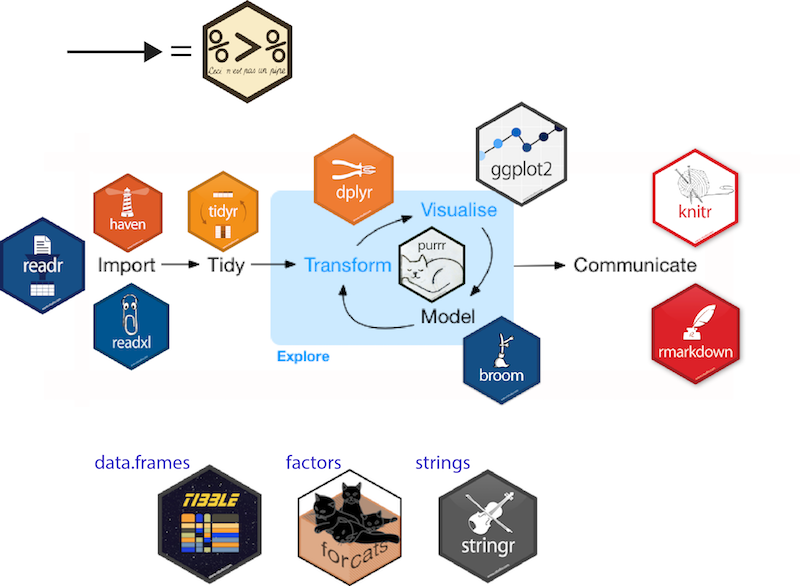
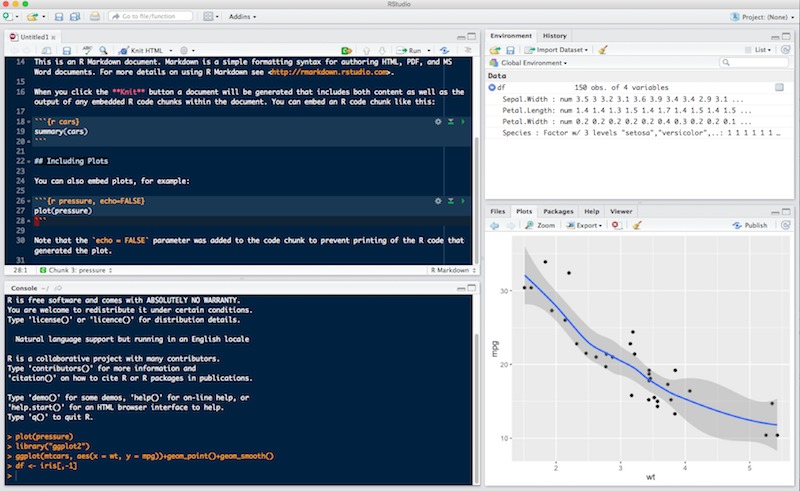
The goal is to learn statistics applied to biology using  and its dialect
and its dialect ![]()
This course of ~ 60 hours is composed of:
lectures
- slides, formal lecture
- quick exercices inserted
- unprepared live demo
practical sessions
- detailed exercices
- solutions available
project
- team up by (2, 3)
- due date: mid-Dec
- defend 17th Dec
3 ECTS
- written exam
- 2 hours
- no document allowed
3 ECTS
- practical exam,
Rmdfile - 2 hours
- all document allowed
- internet allowed
1 ECTS
- home work
- questions at anytime aurelien.ginolhac@uni.lu